Research finds urban social networks are not determined geographically, but socially
Until now, studies of human interactions through mobile communication and social media have always been conducted at the country scale—using broad strokes to produce illustrations of society’s social networking tendencies. These explorations have concluded that social networks and contacts are primarily created in relation to geographic proximity.
Now, a new study led by MIT researchers bridges the gap between country and city, employing a novel method to explore the dynamic structure of social networks on the urban scale. The study, published this week in Scientific Reports, shows that urban networks are not determined geographically as traditionally thought, but rather socially.
“I was interested to investigate the relationship of social networks and human distance with the built environment and urban transportation,” says Department of Civil and Environmental Engineering (CEE) Associate Professor Marta González, co-author of the paper. “We found that geography plays only a minor role when forming social networking communities within cities. Unlike the country, cities have more dispersed communities.” Understanding how information spreads between social networking communities within a city will be crucial in the implementation of sustainable urban practices and policies in the future, she added.
The research grew from earlier explorations of expansive geolocated communication datasets. Gonzalez said that while the structure of communities was always analyzed before at the country scale, the urban scale had yet to be explored—this fueled her team’s mission to understand how social networks relate to their physical space.
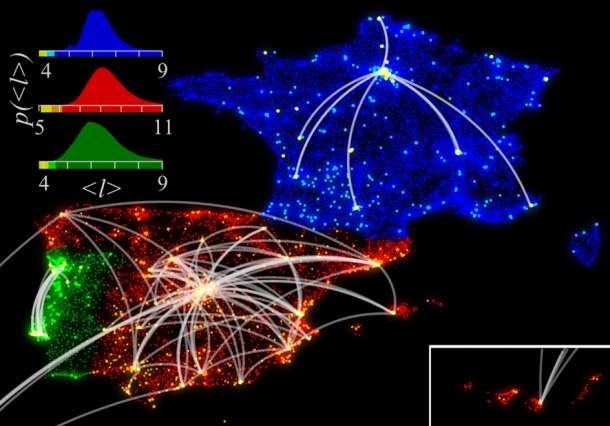
Through the observation of social networks within urban boundaries, the team presents a new perspective on an established study of searchability in self-organized networks. The study extracted phone data from over 25 million phone users, from three countries, over the course of six months. The information was used to systematically outline the structure of network communities within a city.
“We were able, for the first time, to observe how social networks work on a urban scale and their searchability implications,” said lead author Carlos Herrera-Yagüe, of the Technical University of Madrid. Their study, he continued, built the social network that emerged from billions of mobile phone interactions across three countries, in a much higher spatial resolution provided from mobile phone towers.
The paper was co-authored Gonzalez, principal investigator on the study; Herrera-Yaque, lead author; former CEE postdoc Christian Schneider ’13, Rosa Maria Benito and Pedro Zufira professors from Technical University of Madrid, and Zibigniew Smoreda from Orange Labs.
Mobile interactions
Gonzalez and her team systematically demonstrated that cities change the structure of social networks. Using data from 7 billion mobile phone interactions from 155 cities in Spain, France, and Portugal, they explored the role of both social and geographic distances in social networks.
They concluded that urban networks are not determined by geographic proximity, but rather social distance. That is to say, groups of individuals with comparable interests, hobbies, and careers form communities within their city’s social networks.
According to Gonzalez, these findings are most likely related to causes such as urban growth and the economic function of cities. “Social distance is hard to define and measure with passive data,” she says. “But it’s important to know where the communities are within social networks, and how they expand.” It’s the social structure of urban communities, not geographic, that makes social networks searchable within cities.
This understanding that content is spread through homophily and not geography has implications for adoptions of innovations and epidemics within social networks, she adds.
“We are envisioning social media apps for social good—in this case, sustainable adoptions in the city,” she says.
In urban planning, the examination of social networks is influential in the development of urban policies that address problems such as segregation and political divisions. The results of this team’s study, Herrera says, prove that humans have built communities that connect people to all resources, while ignoring the vast majority of the social network.
“This is a remarkably difficult challenge that mankind has solved in a self-organized way,” Herrera remarks. The research has the potential to inspire the creation of a new generation of communications and transportation infrastructures that are decentralized and more focused on society’s use of them.
Gonzalez adds that the current research project opens the way for more detailed studies of the subject, noting, “It would be interesting to see if the socioeconomic status of people, their age, and/or gender have a role in the results found.”
With this newly developed model, Gonzalez and her team will continue to study social network groups and their mobility in order to better understand how to effectively spread information through networks.
References:http://phys.org/